This article may contain affiliate links. If you buy some products using those links, I may receive monetary benefits. See affiliate disclosure here
For someone who is not technically inclined, there are many web-related terms that can seem confusing at first - URL, URI, link, hyperlink, permalink, web address, so on. If you feel the same, this post might help you.
All these terms are connected, but not entirely the same. Recently, I read an interesting article by Daniel Miessler discussing how even the creators of these things are sometimes not clear about the different specifications.
So, in this article, we will discuss what URL means. In the end, you should understand the differences between the different terms.
An Introduction to URL
First of all, URL is the abbreviation for Uniform Resource Locator. And that resource can be anything on the internet, not just web pages. For example, the article you are reading right now is a web page with its URL at - /what-does-url-mean/. But as you can see, there are also other resources on this page, like the site logo at the top, which is an image.
So, the resource pointed by a URL can be a web page, or files like images, CSS, JS, etc. Not just web resources, URLs can also point to other types of resources like emails, FTP servers etc. If you have connected to your site using an FTP program like Filezilla, you know that the hostname starts with the ftp:// instead of http:// (more on that below).
But usually, when we speak about a URL, it refers to a web address, that is, the resources accessbile using the HTTP protocol.
With that being said, the first URL in the world is http://info.cern.ch/hypertext/WWW/TheProject.htm. It pointed to the first-ever web page created by Tim-Berners Lee at CERN, Switzerland in 1991.
You might also like:
Parts of a URL
On a basic level, a URL is a string. It contains alphabets, numbers, and some other characters (more on that below). But, if you look at the address bar in your browser for any website, you can find that the URL is not just a plain string. We can divide it into different parts, mainly five:
- Protocol/scheme
- Domain name
- Path
- Query String
- Fragment Identifier
Let us look at each of these parts on by one:
Protocol or Scheme
In my article about how the internet works, I had mentioned that there are a set of protocols that define how communication over the internet happens. It's called TCP/IP (Transmission Control Protocol/Internet Protocol). For the web, the protocol is HTTP, which is a subset of TCP/IP.
The protocol part contains a few letters followed by a colon and two forward slashes.
Highlight the address bar on your browser and you can see that all web addresses start with either http:// or https://. The latter is just HTTP with SSL or TLS encryption, which ensures security.
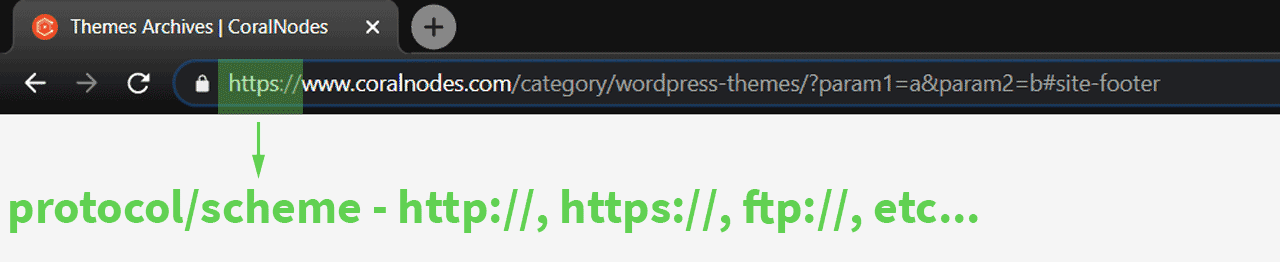
The default protocol used by all major web browsers is HTTP. So, even if you don't explicitly add it at the beginning of an address when visiting a site, the browser knows what to do. These days, almost all websites force SSL or TLS connections (HTTPS redirection). Even if you use HTTP://, the server will redirect the browser to https://.
HTTP or HTTPS are the protocols for the web.
Domain Name
Next comes the domain name part. Unlike the protocol, it is unique to each website. Again, a domain name includes multiple parts, mainly:
- subdomain(s)
- second-level domain
- top-level domain or extension
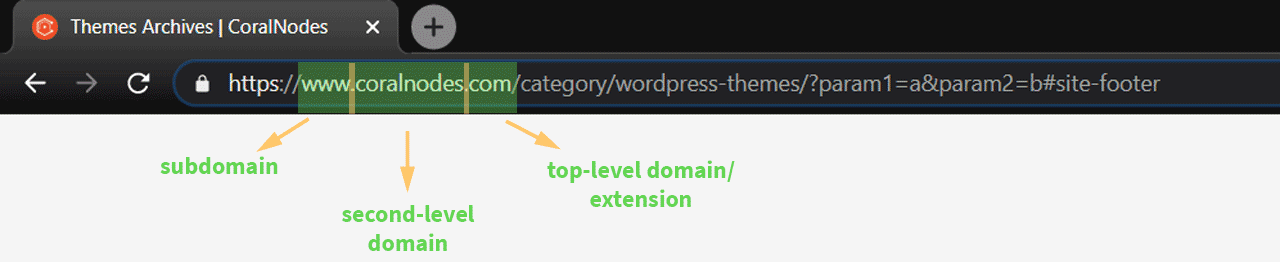
Usually, a subdomain is used to deliver a different section of a website. For example, you might have seen some sites using a subdomain blog.example.com for their blog section. Here, the blog is called a subdomain of the main domain example.com. Whether you use a subdomain or not is optional.
If you have used free website builders or blogging platforms, then your site will be on a subdomain. For example, when you start a site on Google Blogger, the address will be yoursite.blogspot.com, where yoursite is a subdomain of blogspot.com.
There can also be multiple subdomain levels, like sub2.sub1.example.com. But complicating URL structures like that is not great for a user-friendly website.
The second-level domain is the part just before the extension. On this website, coralnodes is the second-level domain. This part denotes the identity of a site.
And the final part is the extension or top-level domain. There are several TLDs available for the public to register, out of which .com, .net, .org, etc are the most popular choices. There are also country-code TLDs and TLDs with more than one part, such as .in for India, and .co.in.
All the important things related to domain names are managed by the ICANN and its associated organizations.
When you purchase a new domain name, you register both the second-level domain and the top-level domain. Subdomains need not be registered, instead, they are set later at the server-level.
Path
The path comes after the domain name. It can also have multiple levels separated with a forwarding slash. Usually, the root domain name, that is the domain name without any path, points to the home page of a website. While URLs with paths point to the different pages and files on the website.
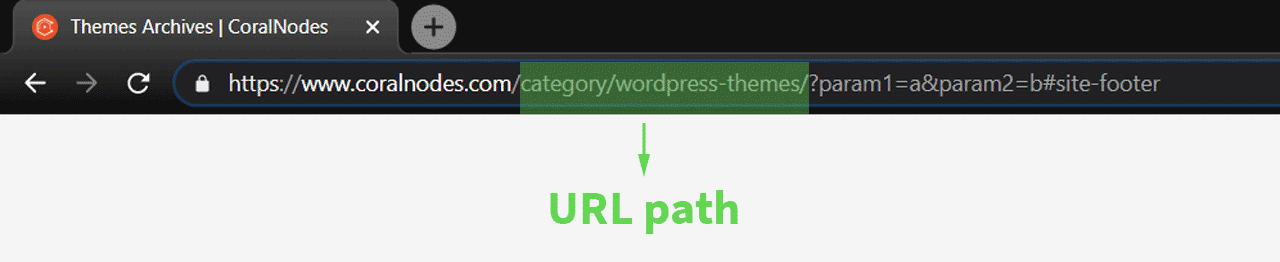
If you have used WordPress, you might have heard about the term 'slug'. It denotes the last part of the path that uniquely identifies a post/page in WordPress, which is set on the post editor.
For example, suppose your WordPress site has a post at the address https://www.example.com/reviews/best-dslr-cameras/. Here, the path is /reviews/best-dslr-cameras/ while the slug is best-dslr-cameras.
Query Strings
Query strings, also known as URL parameters, comes after the path starting with a question mark. Its use-cases are:
- Used by dynamic sites to generate pages on the server
- For adding marketing parameters at the end of URLs (heard about UTM parameters?)
- Cache busting - adding a query string at the end of static files helps to disable browser caching
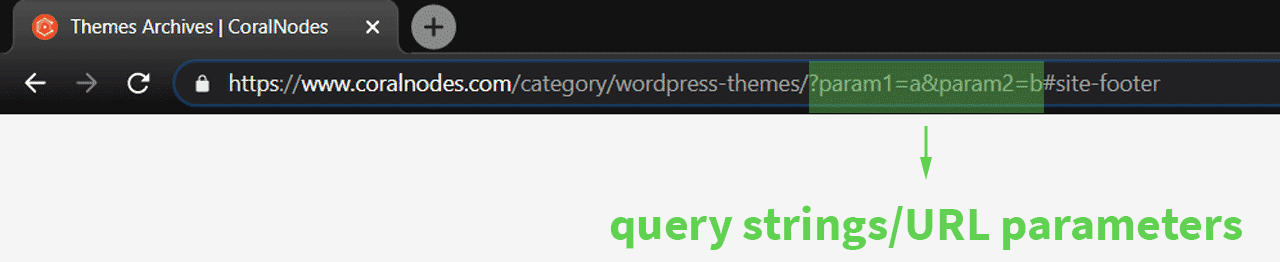
Also, some social media platforms like Facebook add parameters at the end when you share links on them (example.com/page/?fbclid=somestring). It is for marketing purposes to better track link clicks.
Fragment Identifier
Fragment identifiers come last, after any query strings. It starts with a hash sign. If a URL contains such an identifier, the browser looks for any element with that ID and jumps to that part. It is usually used to link to a specific section on the webpage, like headings.
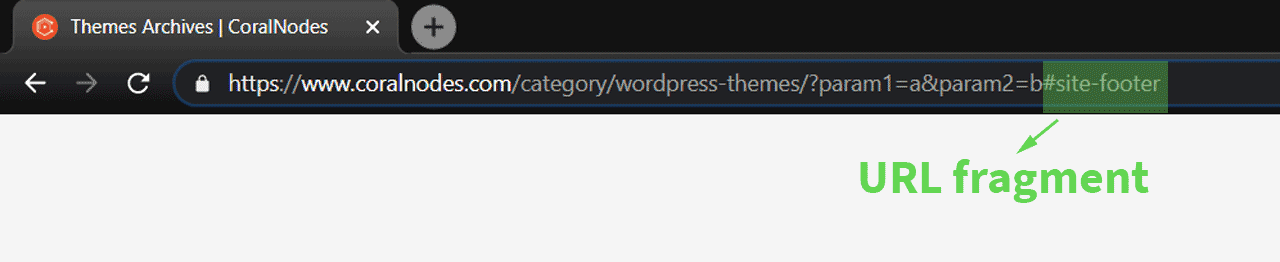
Another name for identifiers is anchors. For example, the anchor for this section is coralnodes.com/what-does-url-mean/**#url-parts**. In WordPress, you can set this ID under the Advanced section for each block.
URL Best Practices for SEO and User Experience
If you are a website owner, here are a few tips to set up great-looking URLs.
According to this article on Moz, URL structure is only a minor ranking factor. Other on-page SEO factors like quality content and speed optimization have more importance. So, the primary goal of setting proper SEO structures is to provide a better user experience.
And for that, here are a few best practices:
Avoid using Special Characters and Spaces
When setting the URL for web pages, always try to use only alphabets and numbers, preferably in lowercase. To separate the words, you can use hyphens, rather than underscores.
URL supports only ASCII characters. So it is better to avoid unsafe characters including spaces. If it contains unsafe characters, the browser will have to encode it before sending, which can result in inconsistencies.
Use Numbers & Dates only When Required
Technically, using numbers in URLs is okay. But for semantics, it may not always be great. For example, when I started my first blog, the URL contained the month and year of publishing, like mysite.com/2012/06/mypost.html. I was using the free Blogger platform, so I had no option to change it. I kept updating the posts, and over time, the date in the URL became irrelevant.
For timeless content on your site, this might make your readers think that your posts are outdated, even if you update them regularly. But despite that, it has no effect on SEO, as far as I know.
On the other hand, for news articles and blog posts with timely nature, adding date might be relevant.
The same is the case for numbers. For example, I published a post with the title '10 best photography themes for WordPress'. But I chose to keep the url as example.com/best-photography-themes/ instead of example.com/10-best-photography-themes/. Why? Because if I later decide to add a few more items to the list, the number ten in the URL will become irrelevant.
Otherwise, if a number is permanent to the content, then it is completely okay to use it. For example, camera lenses usually have their focal length as part of their name. And if you are writing a lens review, you should include that in the URL slug. Example - yoursite.com/canon-70-200mm-review/.
Remember, changing the URL every time when content changes is a big no-no. Doing so will result in an SEO rank loss. So, when crafting URL strings, plan for the long term.
Keep Slugs Short & Meaningful
When creating slugs for pages, try to keep it short and meaningful. Upto three or four words in the slug are okay. More than that, the URL can be too long, not just for search engines, but for the visitors as well. While there aren't any hard rules on how long an SEO URL should be, try to keep it below a hundred characters, including the domain name (the maximum allowed length is said to be 2MB in Chrome, though).
That's why you should choose shorter domain names.
Also, try to include your main keyword or keyphrase in the slug. Another thing you can do to make short URLs is avoiding unnecessary stop words. For example, common English words - a, the, in, etc - are called stop words. I won't say that you should avoid them altogether. Because sometimes they are necessary to convey the meaning.
So, use stop words sensibly.
Use Canonical Tags if Needed
Ideally, a page on your site should be accessible from a single URL only. Otherwise, search engines can treat it as duplicate content, which is bad for SEO.
One thing you can do to prevent such an issue is to set up proper redirects. For example, if you are using www in front of the domain name, make sure you redirect all non-www pages to the www version, and vice-versa.
To take it one step further, use canonical tags. It looks like:
<link rel="canonical" content="https://www.example.com/sample-page/">If you are using WordPress with Yoast or other SEO plugins, it will be taken care of automatically. View the HTML source of a page to ensure that the document's head section contains the canonial tag.
Another use of the canonical tag is when sharing your articles to other platforms. For example, when you share a blog post originally published on your domain to Medium, you can set the canonical tag to the URL of the post on your domain. This ensures that you don't have duplicate content on two different domains.
Set Meaningful URL Paths
In the above points, we were discussing mainly about setting the slug, which is the last part of the URL path.
But, what about the whole path? Should you use a folder-like structure or not?
For example, I write camera reviews on one of my blogs. And suppose I have a review of the Nikon D850 camera. For that, these are some of the path styles that I can implement:
example.com/nikon-d850-review/ - plain & simpleor
example.com/reviews/nikon-d850/ - hierarchical
or
example.com/reviews/cameras/nikon-d850/ - more hierarchical
The second and third URLs use a folder-like path, while the first one is plain and simple. Which one is better?
The answer depends on your site architecture. If the site has diverse content with multiple categories and content types, then folder-style paths make more sense. Suppose the above site also has other sections for lens reviews and photography tutorials. Then the paths can be example.com/reviews/lens/nikon-macro-105/, example.com/tutorials/macrophotography-guide/, like that.
A few points you should keep in mind when creating URL paths are:
- Avoid repeating the same words (e.g., use /reviews/nikon-d850/ rather than /reviews/nikon-d850-review/)
- Don't stuff keywords: include only the main keywords rather than stuffing all the keywords you want to rank.
- If you are not sure about the category names, then it is better not to use categories as folder names in the URL. In case you want to re-organize the site, then category-based URLs can pose a problem.
If you look at the URLs on this blog, you can see that I am using plain URL structures without category bases. Because the topics on this site are not as diverse to justify the use of hierarchical paths. Anyway, the idea is to give a good user experience.
Setting up URL Structure in WordPress
WordPress is a dynamic content management system built with PHP and MySQL. So, the default URLs are based on query strings, which is not that user-friendly.
To set up pretty permalinks, go to the Settings > Permalinks section in your WordPress admin. There you can find the various structures WordPress supports. You can also set up custom structures if you want. I have a video on how to do that:
That's about setting the permalink structure for the whole site. And for each individual post or page, you can set the slug from the post editor.
Absolute & Relative URLs
By now, you understand that a URL locates a resource on the web. Based on how you use the URL, we can divide it into two types:
- Absolute URLs
- Relative URLs
Absolute URL is the full URL starting with protocol, while a relative URL is relative to a particular domain. It does not contain the protocol and domain part.
Examples:
- https://www._example.com/nikon-d850/_ - Absolute URL
- /nikon-d850/ - Relative URL
To access a web page from the browser's address bar, we have to use the absolute URL. Whereas for linking to another page on the same domain using HTML anchor tag, we can use either absolute or relative URL.
| Usage | Absolute URL | Relative URL |
| Link to another page on the same domain | yes | yes |
| Link to a page on another domain/subdomain | yes | no |
| Browser's address bar | yes | no |
URL FAQs
What does URL stand for?
Uniform Resource Locator.
What is the difference between URL and URI?
As its full-form says, a URL locates a resource with protocol, domain, and paths (if any). Whereas a URI need not locate a resource. Also, all URLs are URIs, but not vice-versa.
Is URL and Domain name the same?
No, domain name is only a part of the URL.
Is URL & web address the same?
Almost. Web address is a common term for a URL.
What is a permalink?
Permalink is also URL, but it is supposed to be the permanent address of a resource.



